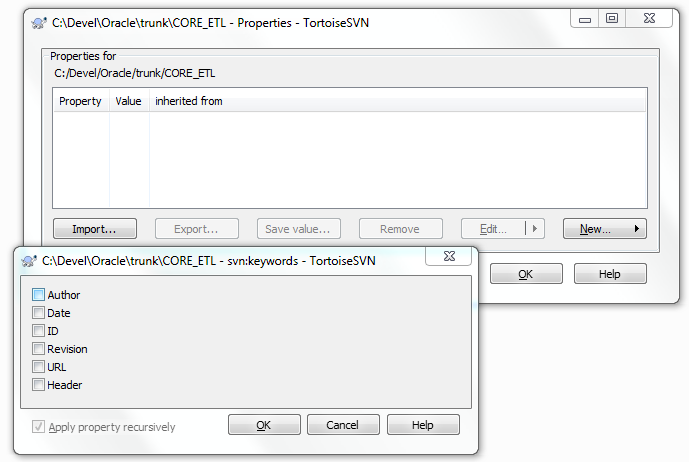
If you are using Subversion-Keywords in you PLSQL-Project you can automatically get the info for all these Keywords for Packages, Procedures and Functions.
Just use a function get_svn_info to find out, which version, date and so on are located actually in you database:
Funcion-Declaration for the Package-Header:
/**
*
* Gibt die Subversion-Informationen des Package-Bodies zurueck
* @is_type mögliche Ausprägungen:
* 'version','url','autor','datum','all'
* default: 'version'
* @return angeforderte Subversion-Info des Package Bodies
*/
FUNCTION get_svn_Info
(is_type IN VARCHAR2 DEFAULT 'version')
RETURN VARCHAR2;
Record-declaration in the Package-Body:
TYPE typ_svn_info IS RECORD (
version VARCHAR2 (256) := '$Rev: 209690 $',
autor VARCHAR2 (256) := '$Author: authorname $',
datum VARCHAR2 (256) := '$Date: 2016-02-09 09:32:47 +0100 (Di, 09. Feb 2016) $',
url VARCHAR2 (256) := '$URL: svn://dir1/oracle/trunk/myschema/MYSCHEMA.MYPACKAGE.packbody $'
);
And the function itself in the Package-Body:
/**
*
* Gibt die Subversion-Informationen des Package-Bodies zurueck
* @is_type mögliche Ausprägungen:
* 'version' oder 'revision','url','autor','datum','name','all'
* default: 'version'
* @return angeforderte Subversion-Info des Package Bodies
*/
FUNCTION get_svn_Info
(is_type IN VARCHAR2 DEFAULT 'version')
RETURN VARCHAR2
is
c_convert varchar2 (4000);
infos typ_svn_info;
begin
case lower(is_type)
when 'version' then c_convert := infos.version;
when 'revision' then c_convert := infos.version;
when 'url' then c_convert := infos.url;
when 'autor' then c_convert := infos.autor;
when 'datum' then c_convert := infos.datum;
when 'name' then c_convert := substr (infos.url,instr(infos.url,'/',-1)+1); -- name = part after the last slash
when 'all' then
c_convert := get_svn_Info('url')
||' Ver.'||get_svn_Info('version')
||' von:'||upper(get_svn_Info('autor'))
||' letzte Aenderung:'||get_svn_Info('datum')
;
return c_convert;
else
return 'Parameter existiert nicht! (all, autor, url, datum, version, name)';
end case;
c_convert := replace(c_convert,'$','');
c_convert := trim(substr(c_convert,instr(c_convert,':',1,1)+1));
return c_convert;
exception
when others then return '-1';
end get_svn_info;
Examplecall:
set serveroutput on
exec dbms_output.put_line(myschema.mypackage.get_svn_Info('name')||' '||myschema.mypackage.get_svn_Info('Revision')||' vom '||myschema.mypackage.get_svn_Info('datum')||' ('||myschema.mypackage.get_svn_Info('autor')||')');
Result:
myschema.my_package.packbody 209690 vom 2016-02-09 09:32:47 +0100 (Di, 09. Feb 2016) (authorname)